

使用spaCy进行大规模数据分析
数据结构 (1): Vocab, Lexemes和StringStore
Vocab: 存储那些多个文档共享的数据- 为了节省内存使用,spaCy将所有字符串编码为哈希值。
- 字符串只在
StringStore中通过nlp.vocab.strings存储一次。 - 字符串库:双向的查询表
|
1 2 3 |
nlp.vocab.strings.add("咖啡") coffee_hash = nlp.vocab.strings["咖啡"] coffee_string = nlp.vocab.strings[coffee_hash] |
- 哈希是不能逆求解的,所以我们要提供共享词汇表。
|
1 2 |
# 如果该字符串从未出现过则会报错 string = nlp.vocab.strings[7962530705879205333] |
- 在
nlp.vocab.strings中查找字符串和哈希值
|
1 2 3 |
doc = nlp("我爱喝咖啡。") print("hash value:", nlp.vocab.strings["咖啡"]) print("string value:", nlp.vocab.strings[7962530705879205333]) |
|
1 2 |
hash value: 7962530705879205333 string value: 咖啡 |
doc也会暴露出词汇表和字符串
|
1 2 |
doc = nlp("我爱喝咖啡。") print("hash value:", doc.vocab.strings["咖啡"]) |
|
1 |
hash value: 7962530705879205333 |
Lexemes: 词汇表中的元素
- 一个
Lexeme实例是词汇表中的一个元素
|
1 2 3 4 5 |
doc = nlp("我爱喝咖啡。") lexeme = nlp.vocab["咖啡"] # 打印词汇的属性 print(lexeme.text, lexeme.orth, lexeme.is_alpha) |
|
1 |
咖啡 7962530705879205333 True |
- 包含了一个词的和语境无关的信息
- 词组的文本:
lexeme.text和lexeme.orth(哈希值) - 词汇的属性如
lexeme.is_alpha - 并不包含和语境相关的词性标注、依存关系和实体标签
- 词组的文本:
Vocab, 哈希值和语素
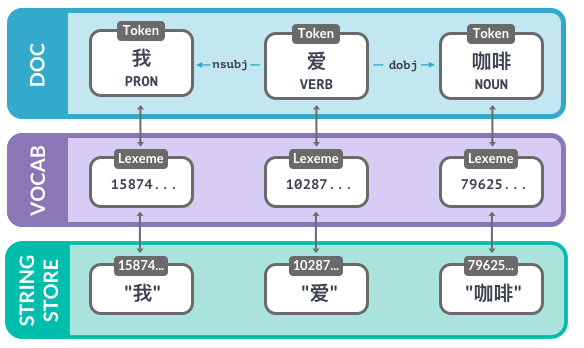
从字符串到哈希值
- 在
nlp.vocab.strings中查找字符串”猫”来得到哈希值。 - 查找这个哈希值来返回原先的字符串。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import spacy nlp = spacy.load("zh_core_web_sm") doc = nlp("我养了一只猫。") # 查找词汇"猫"的哈希值 cat_hash = nlp.vocab.strings["猫"] print(cat_hash) # 查找cat_hash来得到字符串 cat_string = nlp.vocab.strings[cat_hash] print(cat_string) |
返回结果如下
|
1 2 |
12262475268243743508 猫 |
- 在
nlp.vocab.strings中查找字符串标签”PERSON”来得到哈希值。 - 查找这个哈希值来返回原先的字符串。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import spacy nlp = spacy.load("zh_core_web_sm") doc = nlp("周杰伦是一个人物。") # 查找标签是"人物"的字符串的哈希值 person_hash = nlp.vocab.strings["人物"] print(person_hash) # 查找person_hash来拿到字符串 person_string = nlp.vocab.strings[person_hash] print(person_string) |
返回结果如下
|
1 2 |
16486493800568926464 人物 |
数据结构(2):Doc、Span和Token
Doc是spaCy的核心数据结构之一。 当我们用nlp实例来处理文本时Doc就会被自动创建, 当然我们也可以手动初始化这个类。
创建nlp实例之后,我们就可以从spacy.tokens中导入Doc类。
这个例子中我们用了三个词来创建一个doc。空格存储在一个布尔值的列表中, 代表着对应位置的词后面是否有空格。每一个词符都有这个信息,包括最后一个词符!
Doc类有三个参数:共享的词汇表,词汇和空格。
创建一个Doc
- 从
spacy.tokens中导入Doc - 用
words和spaces创建一个Doc。别忘了把vocab传进去!
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
import spacy nlp = spacy.blank("en") # 导入Doc类 from spacy.tokens import Doc # 目标文本:"spaCy is cool!" words = ["spaCy", "is", "cool", "!"] spaces = [True, True, False, False] # 用words和spaces创建一个Doc doc = Doc(nlp.vocab, words=words, spaces=spaces) print(doc.text) |
返回结果如下
|
1 |
spaCy is cool! |
从头开始练习Docs(文档), spans(跨度)和entities(实体)
- 从
spacy.tokens中导入Doc和Span。 - 用
Doc类使用词组和空格直接创建一个doc实例。 - 用
doc实例创建一个”David Bowie”的Span,赋予它"PERSON"的标签。 - 用一个实体的列表,也就是”David Bowie”
span,来覆盖doc.ents。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
import spacy nlp = spacy.blank("zh") # 导入Doc和Span类 from spacy.tokens import Doc, Span words = ["我", "喜欢", "周", "杰伦"] spaces = [False, False, False, False] # 用words和spaces创建一个doc doc = Doc(nlp.vocab, words=words, spaces=spaces) print(doc.text) # 为doc中的"周杰伦"创建一个span,并赋予其"PERSON"的标签 span = Span(doc, 2, 4, label="PERSON") print(span.text, span.label_) # 把这个span加入到doc的实体中 doc.ents = [span] # 打印所有实体的文本和标签 print([(ent.text, ent.label_) for ent in doc.ents]) |
返回结果如下
|
1 2 3 |
我喜欢周杰伦 周杰伦 PERSON [('周杰伦', 'PERSON')] |
数据结构最佳实践
- 在
doc中遍历每一个token并检查其token.pos_属性。 - 用
doc[token.i + 1]来检查下一个词符及其.pos_属性 - 如果找到一个处于动词前的专有名词,我们就打印其
token.text。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import spacy nlp = spacy.load("zh_core_web_sm") doc = nlp("北京是一座美丽的城市。") # 遍历所有的词符 for token in doc: # 检查当前词符是否是一个专有名词 if token.pos_ == "PROPN": # 检查下一个词符是否是一个动词 if doc[token.i + 1].pos_ == "VERB": print("找到了动词前面的一个专有名词:", token.text) |
返回结果如下
|
1 |
找到了动词前面的一个专有名词: 北京 |
词向量和语义相似度
spaCy可以对比两个实例来判断它们之间的相似度Doc.similarity()、Span.similarity()和Token.similarity()- 使用另一个实例作为参数返回一个相似度分数(在
0和1之间) - 注意:我们需要一个含有词向量的流程,比如:
- ✅
en_core_web_md(中等) - ✅
en_core_web_lg(大) - 🚫 而不是
en_core_web_sm(小)
- ✅
- 相似度是通过词向量计算的
- 词向量是一个词汇的多维度的语义表示
- 词向量是用诸如Word2Vec 这样的算法在大规模语料上面生成的
- 词向量可以是spaCy流程的一部分
- 默认我们使用余弦相似度,但也有其它计算相似度的方法
Doc和Span的向量默认是由其词符向量的平均值计算得出的- 短语的向量表示要优于长篇文档,因为后者含有很多不相关的词
检查词向量
- 读取中等大小的
"zh_core_web_md"流程,该流程含有词向量 - 用
token.vector属性来打印"老虎"的向量。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
import spacy # 读取zh_core_web_md流程 nlp = spacy.load("zh_core_web_md") # 处理文本 doc = nlp("两只老虎跑得快") for token in doc: print(token.text) # 获取词符"老虎"的向量 laohu_vector = doc[2].vector print(laohu_vector) |
返回结果如下
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
两 只 老虎 跑 得 快 [ 5.7924e-01 -2.6305e-01 -1.4191e-01 -5.0995e+00 3.8716e+00 3.5153e+00 -6.9870e-01 2.6803e+00 -9.4611e-01 5.0214e+00 1.6222e+00 1.5286e+00 8.7571e-01 2.6110e+00 2.3262e-01 2.5249e+00 -1.6588e+00 1.8337e+00 -2.5249e+00 3.8427e+00 2.6680e+00 -8.2123e-01 1.6126e+00 -3.7706e+00 3.8015e+00 7.8155e-02 1.5115e+00 2.8359e-01 3.1309e+00 1.5774e+00 -5.5651e-01 -1.7239e+00 -3.7953e+00 -6.6034e-01 -9.2233e-01 4.9122e-01 -1.4692e+00 -2.8478e+00 -4.9413e+00 -2.4462e+00 1.6943e+00 2.3306e+00 8.0750e-01 2.1319e+00 3.7470e+00 2.7392e+00 3.2851e+00 3.2695e+00 2.8855e+00 -1.7605e+00 -5.0122e-01 -3.4106e-01 -3.4631e+00 7.9958e-01 -1.7841e+00 1.5095e-01 -2.5067e+00 4.1346e-01 -3.0813e-01 6.0523e-02 -1.8828e+00 8.6008e-01 -2.3530e+00 1.5310e+00 5.9555e-01 -1.6424e+00 -1.4507e+00 1.9775e+00 -2.0973e+00 -4.8088e-01 -6.6589e-01 1.2523e+00 1.5388e+00 -3.8856e+00 -1.0470e+00 -6.1471e-01 -1.2202e+00 3.0140e+00 -2.5228e+00 -2.5406e+00 -3.6240e-01 1.1047e+00 -3.6204e-01 -1.7201e+00 -8.3483e-01 4.8543e-01 3.7905e+00 -1.3421e+00 2.5667e+00 -3.0803e+00 7.0080e-01 -1.6625e+00 -2.9501e+00 3.7953e+00 1.6391e+00 1.4627e-01 -1.5337e+00 1.0313e+00 -3.5355e-01 -3.1553e+00 3.5077e+00 -8.6935e-01 1.2467e+00 1.0013e+00 -2.3039e+00 -1.2872e+00 -2.9164e+00 9.3474e-01 1.4428e+00 4.6318e-01 -2.0986e+00 -1.4509e+00 2.2329e+00 -4.9564e+00 4.4020e+00 -2.2259e+00 -1.3311e+00 -2.4513e+00 -2.2716e+00 -3.0772e+00 4.0158e+00 1.0085e+00 1.5054e+00 3.3241e-01 -4.6241e-02 3.3969e+00 -5.1220e-01 -3.8713e-01 -1.0150e+00 5.6705e-01 7.6756e-02 -3.7357e+00 9.6764e-01 7.2549e-01 1.1777e+00 5.2911e+00 -7.7748e-01 -2.3084e+00 2.9886e+00 5.4346e-03 2.1386e+00 -2.2922e+00 5.7575e+00 -1.6354e+00 6.2101e-01 1.0835e+00 -2.4092e+00 -3.2485e+00 6.4983e-01 -3.1658e+00 7.6660e-01 1.9486e-01 1.0793e+00 -2.8382e+00 -3.5696e+00 -1.6425e+00 -5.3510e+00 1.6940e+00 8.6598e-01 -1.0292e+00 -3.1180e+00 -1.9218e+00 2.2785e+00 1.7752e+00 1.2698e-01 -2.0594e+00 -3.8164e+00 2.4909e+00 6.5976e-01 -1.4267e+00 1.7071e+00 1.2723e+00 8.1331e-01 1.6400e+00 6.0527e-01 9.4689e-01 4.1356e+00 1.4681e+00 1.4932e+00 1.0531e+00 1.3132e+00 2.5008e+00 6.9717e-01 8.0326e-01 -9.8515e-01 3.6686e-01 1.3508e+00 -8.1932e-01 -3.8115e+00 2.4958e+00 -1.3414e+00 2.5231e+00 1.8265e+00 -5.3526e+00 1.2001e+00 -1.3428e+00 1.7890e+00 -8.8131e-01 1.5124e+00 -3.9097e-01 -1.9924e+00 -2.0793e+00 3.4676e+00 4.1675e-01 -3.0836e+00 -3.6522e-01 1.0776e-01 2.4466e-01 1.8187e+00 -1.0750e+00 -7.6324e-01 -1.9996e-02 -2.4298e+00 9.1939e-01 7.0144e-01 2.8980e+00 -2.0506e+00 -1.2472e+00 -2.6498e+00 -8.1173e-01 -9.3867e-01 3.8803e+00 8.0914e-01 1.3228e+00 -6.7176e-01 1.2085e+00 -2.2681e+00 -1.7464e+00 1.9539e+00 -2.0198e+00 -6.7864e-01 -5.4648e-01 2.4023e-01 1.4373e-01 -1.1620e+00 8.7375e-01 -2.1149e+00 7.5399e-01 -1.0126e+00 1.5917e+00 1.4630e+00 2.1774e+00 -2.6580e+00 -1.0528e+00 -1.3980e+00 1.4976e+00 -6.3626e-01 -2.4981e+00 -2.8563e+00 1.6434e+00 -1.0439e+00 8.2653e-01 1.1626e+00 -4.8317e+00 2.0123e-01 -9.5807e-02 -2.1817e+00 -1.6966e+00 4.2981e-02 -7.2740e-01 3.8890e+00 -3.2062e-01 2.0124e-01 -7.4209e-01 -5.9732e+00 -4.1930e+00 -8.3220e-01 -2.7868e+00 -5.9619e-01 -2.0681e+00 1.1154e+00 1.0995e+00 -4.2168e+00 3.1343e+00 -4.1112e+00 1.5323e+00 -1.0445e+00 1.5628e+00 1.1194e-01 3.8676e+00 -1.4527e-01 -1.8744e+00 -5.7825e-01 -3.4847e-01 -2.7685e+00 -7.6714e-01 2.0325e-01 7.3041e-01 2.5122e-01 1.0219e+00 1.2716e+00 -1.0849e+00 -1.2975e+00 -1.3038e+00 1.1385e+00 2.0639e+00 -4.1764e+00 3.1660e+00 1.5245e+00 2.5270e+00] |
比对相似度
使用doc.similarity方法来比较doc1和doc2的相似度并打印结果。
|
1 2 3 4 5 6 7 8 9 10 |
import spacy nlp = spacy.load("zh_core_web_md") doc1 = nlp("这是一个温暖的夏日") doc2 = nlp("外面阳光明媚") # 获取doc1和doc2的相似度 similarity = doc1.similarity(doc2) print(similarity) |
返回结果如下
|
1 |
0.5488376705728557 |
使用token.similarity方法来比较token1和token2的相似度并打印结果。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
import spacy nlp = spacy.load("zh_core_web_md") doc = nlp("电影和音乐") for i, token in enumerate(doc): print(i, token.text) token1, token2 = doc[0], doc[2] # 获取词符"电影"和"音乐"的相似度 similarity = token1.similarity(token2) print(similarity) |
返回结果如下
|
1 2 3 4 |
0 电影 1 和 2 音乐 0.32749295 |
- 为”不错的餐厅”/“很好的酒吧”创建跨度(span)。
- 使用
span.similarity来比较它们并打印结果。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
import spacy nlp = spacy.load("zh_core_web_md") doc = nlp("这是一家不错的餐厅。之后我们又去了一家很好的酒吧。") for i, token in enumerate(doc): print(i, token.text) # 给"不错的餐厅"和"很好的酒吧"分别创建span span1 = doc[2:5] span2 = doc[12:15] # 获取两个span的相似度 similarity = span1.similarity(span2) print(similarity) |
返回结果如下
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
0 这是 1 一家 2 不错 3 的 4 餐厅 5 。 6 之后 7 我们 8 又 9 去 10 了 11 一家 12 很 13 好的 14 酒吧 15 。 0.68062496 |
流程和规则的结合
如果你的应用需要能够根据一些例子而进行泛化,那么统计模型会很有用。
举个例子,训练好的流程通常可以优化产品和人名的识别。 相比于给出一个所有曾经出现过的人名库,你的应用可以判断一段文本中的几个词符是否是人名。 相类似的你也可以预测依存关系标签从而得到主宾关系。
我们可以使用spaCy的实体识别器、依存句法识别器或者词性标注器来完成这些任务。
当我们要查找的例子差不多是有限个的时候,基于规则的方法就变得很有用。比如世界上所有的国家名或者城市名、药品名或者甚至狗的种类。
在spaCy中我们可以用定制化的分词规则以及matcher和phrase matcher这样的匹配器来完成这些任务。
在上一章中,我们学过如何用spaCy的基于规则的匹配器matcher来查找文本中的复杂模板。 这里我们简单回顾一下。
matcher由一个共享词汇表(通常是nlp.vocab)来初始化。
模板是一个元素为字典的列表,每个字典代表了一个词符及其属性。 模板可以用matcher.add添加到matcher中。
运算符可以定义一个词符应该被匹配多少次,比如"+"表示可以匹配一次或者更多次。
在doc实例上调用matcher会返回一个匹配结果的列表。每一个匹配结果是一个元组, 其中包括一个ID以及文档中的词符的起始和终止索引。
短语匹配器phrase matcher是另一个在数据中查找词语序列的非常有用的工具。
短语匹配器也是在文本中做关键词查询,但不同于仅仅寻找字符串,短语匹配器可以直接读取语义中的词符。
短语匹配器将Doc实例作为模板。
短语匹配器也非常快。
所以当我们要在大规模语料中匹配一个很大的字典和词库时这就很有用。
模板调试
- 编辑
pattern1使其可以正确匹配到所有的形容词后面跟着"笔记本"。 - 编辑
pattern2使其可以正确匹配到"锐龙"加上后面的数字 (LIKENUM) 和符号 (ISASCII) 。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
import spacy from spacy.matcher import Matcher nlp = spacy.load("zh_core_web_sm") doc = nlp("荣耀将于7月16日发布新一代 MagicBook 锐龙笔记本,显然会配备7nm工艺、Zen2 架构的" "全新锐龙4000系列,但具体采用低功耗的锐龙4000U 系列,还是高性能的锐龙4000H 系列," "目前还没有官方消息。今天,推特曝料大神公布了全新 MagicBook Pro 锐龙本的配置情况。" ) # 创建匹配模板 pattern1 = [{"POS": "ADJ"},{"TEXT": "笔记本"}] pattern2 = [{"TEXT": "锐龙"}, {"LIKE_NUM": True}, {"IS_ASCII": True}] # 初始化matcher并加入模板 matcher = Matcher(nlp.vocab) matcher.add("PATTERN1", [pattern1]) matcher.add("PATTERN2", [pattern2]) # 遍历匹配结果 for match_id, start, end in matcher(doc): # 打印匹配到的字符串名字及匹配到的span的文本 print(doc.vocab.strings[match_id], doc[start:end].text) |
返回结果如下
|
1 2 |
PATTERN2 锐龙4000U PATTERN2 锐龙4000H |
高效率的短语匹配
- 导入
PhraseMatcher并用含有共享vocab的变量matcher来初始化。 - 加入短语模板并在’doc’上面调用matcher
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
import json import spacy with open("exercises/zh/countries.json", encoding="utf8") as f: COUNTRIES = json.loads(f.read()) nlp = spacy.blank("zh") doc = nlp("智利可能会从斯洛伐克进口货物") # 导入PhraseMatcher并实例化 from spacy.matcher import PhraseMatcher matcher = PhraseMatcher(nlp.vocab) # 创建Doc实例的模板然后加入matcher中 # 下面的代码比这样的表达方式更快: [nlp(country) for country in COUNTRIES] patterns = list(nlp.pipe(COUNTRIES)) matcher.add("COUNTRY", patterns) # 在测试文档中调用matcher并打印结果 matches = matcher(doc) print([doc[start:end] for match_id, start, end in matches]) |
返回结果如下
|
1 |
[智利, 斯洛伐克] |
提取国家和关系
- 对匹配结果进行遍历, 创建一个标签为
"GPE"(geopolitical entity,地理政治实体)的Span。 - 覆盖
doc.ents中的实体,加入匹配到的跨度span。 - 获取匹配到的跨度span中的根词符的头。
- 打印出词符头和跨度span的文本。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
import spacy from spacy.matcher import PhraseMatcher from spacy.tokens import Span import json with open("exercises/zh/countries.json", encoding="utf8") as f: COUNTRIES = json.loads(f.read()) with open("exercises/zh/country_text.txt", encoding="utf8") as f: TEXT = f.read() nlp = spacy.load("zh_core_web_sm") matcher = PhraseMatcher(nlp.vocab) patterns = list(nlp.pipe(COUNTRIES)) matcher.add("COUNTRY", patterns) # 创建一个doc并重置其已有的实体 doc = nlp(TEXT) doc.ents = [] # 遍历所有的匹配结果 for match_id, start, end in matcher(doc): # 创建一个标签为"GPE"的span span = Span(doc, start, end, label="GPE") # 覆盖doc.ents并添加这个span doc.ents = list(doc.ents) + [span] # 获取这个span的根头词符 span_root_head = span.root.head # 打印这个span的根头词符的文本及span的文本 print(span_root_head.text, "-->", span.text) # 打印文档中的所有实体 print([(ent.text, ent.label_) for ent in doc.ents if ent.label_ == "GPE"]) |
返回结果如下
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
内战 --> 萨尔瓦多 任务 --> 纳米比亚 隔离 --> 南非 统治 --> 柬埔寨 授权 --> 美国 入侵 --> 伊拉克 入侵 --> 科威特 莫桑比克 --> 索马里 莫桑比克 --> 海地 南斯拉夫 --> 莫桑比克 包括 --> 南斯拉夫 惨重 --> 美国 行动 --> 索马里 援助团 --> 卢旺达 大屠杀 --> 卢旺达 欧洲 --> 美国 总统 --> 美国 新加坡 --> 英国 紧随 --> 新加坡 撤资 --> 美国 任务 --> 塞拉利昂 陆战队 --> 英国 入侵 --> 阿富汗 入侵 --> 美国 入侵 --> 伊拉克 介入 --> 苏丹 共和国 --> 刚果 内战 --> 叙利亚 内战 --> 斯里兰卡 地震 --> 海地 [('萨尔瓦多', 'GPE'), ('纳米比亚', 'GPE'), ('南非', 'GPE'), ('柬埔寨', 'GPE'), ('美国', 'GPE'), ('伊拉克', 'GPE'), ('科威特', 'GPE'), ('索马里', 'GPE'), ('海地', 'GPE'), ('莫桑比克', 'GPE'), ('南斯拉夫', 'GPE'), ('美国', 'GPE'), ('索马里', 'GPE'), ('卢旺达', 'GPE'), ('卢旺达', 'GPE'), ('美国', 'GPE'), ('美国', 'GPE'), ('英国', 'GPE'), ('新加坡', 'GPE'), ('美国', 'GPE'), ('塞拉利昂', 'GPE'), ('英国', 'GPE'), ('阿富汗', 'GPE'), ('美国', 'GPE'), ('伊拉克', 'GPE'), ('苏丹', 'GPE'), ('刚果', 'GPE'), ('叙利亚', 'GPE'), ('斯里兰卡', 'GPE'), ('海地', 'GPE')] |

